Let's EncryptによるCTログの運用方法
Let's Encryptは、今年の春にCertificate Transparency(CT)ログを立ち上げました。私たちは、他の組織が私たちの取り組みから学べることを願って、構築方法を共有できることを嬉しく思います。CTは急速にインターネットセキュリティインフラストラクチャの重要な要素となっていますが、残念ながら優れたログを実行するのは簡単ではありません。CTコミュニティがこれまでに実施されたことについてより多くを共有すればするほど、エコシステムはより良くなります。
SectigoとAmazon Web Servicesは、CTログの運用コストの大部分をカバーするために寛大なサポートを提供してくれました。「Sectigoは、Let's Encrypt CTログのスポンサーとなることを誇りに思います。この取り組みは、CTエコシステムに必要な強化を提供すると確信しています」と、SectigoのCIOであるEd Giaquintoは述べています。
CTとその仕組みの詳細については、「Certificate Transparencyの仕組み」をお読みになることをお勧めします。
ここに記載されている内容についてご質問がある場合は、コミュニティフォーラムでお気軽にご質問ください。
目標
- 規模: Let's Encryptは、1日に100万件以上の証明書を発行しており、その数は毎月増加しています。私たちのログは、私たちの証明書と他のCAからの証明書の両方を消費できるようにしたいと考えているため、1日に200万件以上の証明書を処理できる必要があります。この増加し続ける証明書数をサポートするために、CTソフトウェアとインフラストラクチャはスケールに合わせて設計する必要があります。
- 安定性とコンプライアンス: ChromiumおよびAppleのCTポリシーに準拠し、24時間以上続く停止なく、99%の稼働率を目標としています。
- シャーディング: CTログのベストプラクティスは、それをいくつかの時間的シャードに分割することです。時間的シャーディングの詳細については、これらのブログ 投稿をご覧ください。
- 低メンテナンス: スタッフの時間は貴重なので、インフラストラクチャのメンテナンスに費やす時間を最小限に抑えたいと考えています。
システムアーキテクチャ
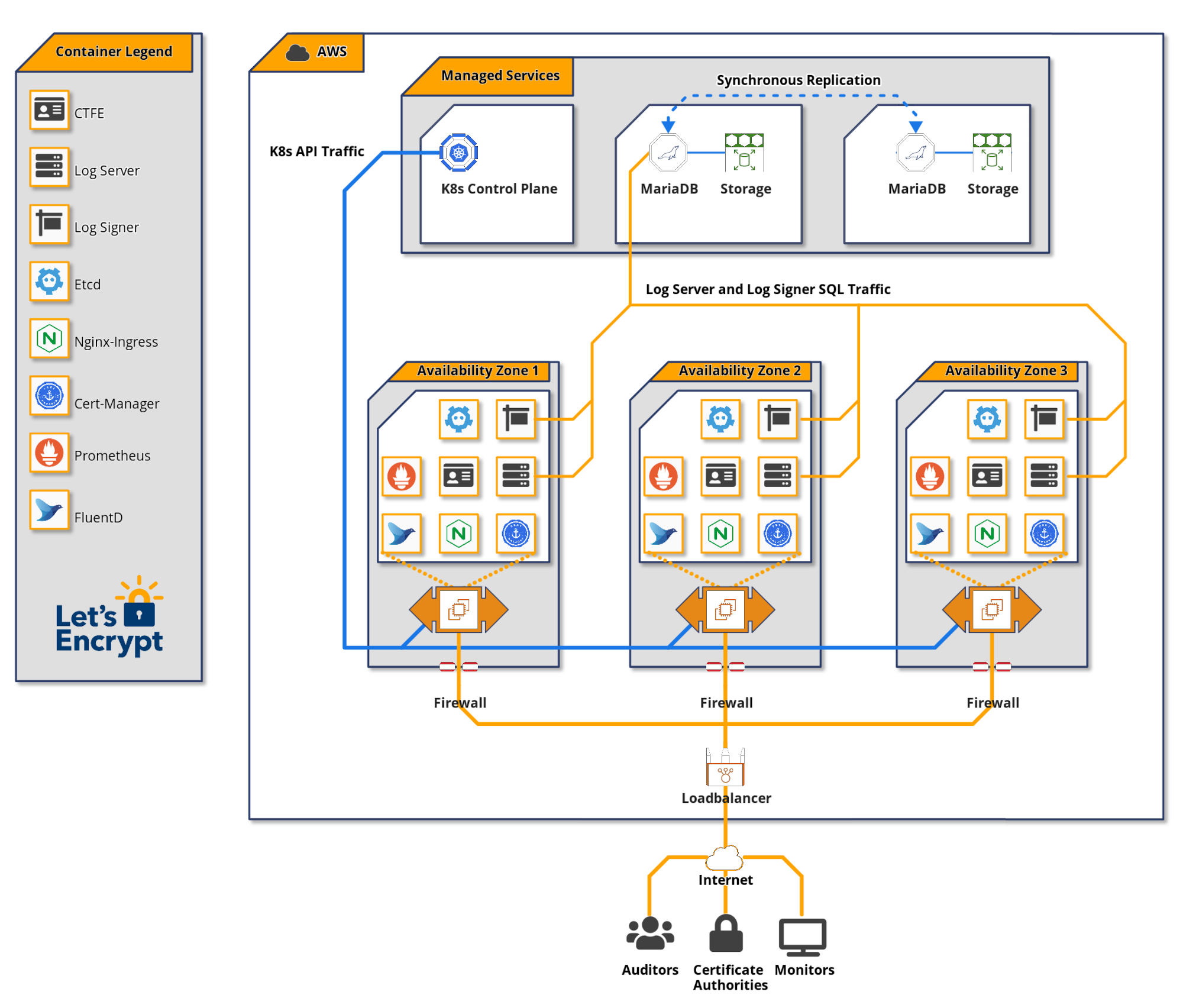
ステージングログと本番ログ
ステージング用と本番用の2つの同等のログを実行しています。本番ログに加える変更はすべて、最初にステージングログにデプロイされます。これは、更新とアップグレードが本番環境にデプロイされる前に問題が発生しないようにするために不可欠です。これらのログへのアクセス details は、ドキュメントに記載されています。
ステージングログは、本番レベルの負荷で継続的に稼働させているため、規模に関連する問題は最初にそこに現れます。また、ステージングCTログを使用して、ステージングCA環境から証明書を送信し、他のCAのステージング環境で使用できるようにしています。
明確にするために、ログはいくつかの時間的シャードで構成されていると考えています。各シャードは技術的には個別のログですが、シャードが単一のログに属していると概念化するのが理にかなっています。
Amazon Web Services (AWS)
2つの理由から、CTログをAWSで実行することにしました。
私たちにとっての1つの考慮事項は、クラウドプロバイダーの多様性でした。エコシステム内の信頼できるログは比較的少ないため、単一のクラウドプロバイダーの停止によって複数のログが停止することは望ましくありません。決定を下した時点では、GoogleとDigital Oceanのインフラストラクチャで実行されているログと、セルフホストのログがありました。AWSで実行されているログは認識していませんでした(後から考えると、DigicertがログにAWSを使い始めていたという事実を見落としていた可能性があります)。CAが使用する信頼できるログのセットアップを検討している場合は、クラウドプロバイダーの多様性を考慮してください。
さらに、AWSは堅牢な機能セットを提供しており、私たちのチームはそれを他の目的で使用した経験があります。AWSがタスクに耐えられるかどうかについては、ほとんど疑問を抱いていませんでした。
Terraform
Let's Encryptは、多くのクラウドベースプロジェクトでHashicorp Terraformを使用しています。既存のTerraformコードを再利用することで、CTログインフラストラクチャをブートストラップすることができました。CTデプロイメントには、EC2、RDS、EKS、IAM、セキュリティグループ、ルーティングなど、約50のコンポーネントがあります。このコードを一元管理することで、小規模なチームでも世界のどのAmazonリージョンでもCTインフラストラクチャを再現し、構成のずれを防ぎ、インフラストラクチャの変更を簡単にテストできます。
データベース
認証局の運用にMariaDBを使用した豊富な経験があるため、CTログデータベースにMariaDBを使用することを選択しました。MariaDBは、私たちが最大の公的に信頼された認証局になるまでの道のりでうまくスケールしてきました。
RDSはスタンバイクラスタメンバーへの同期書き込みを提供するため、MariaDBインスタンスをAmazon RDSで管理することを選択しました。これにより、データベースの自動フェイルオーバーが可能になり、データベースの整合性が保証されます。データベースレプリカへの同期書き込みは、CTログに不可欠です。データベースフェイルオーバー中に1回の書き込みが欠落すると、証明書が約束どおりに含まれず、ログが無効になる可能性があります。RDSにこれを管理してもらうことで、複雑さが軽減され、スタッフの時間が節約されます。データベースのパフォーマンス、チューニング、および監視の管理は引き続き私たちの責任です。
CTログデータベースに必要なストレージ量を慎重に計算することが重要です。ストレージが少なすぎると、時間のかかる、潜在的にリスクの高いストレージ移行が必要になる可能性があります。ストレージが多すぎると、不必要に高いコストが発生する可能性があります。
ストレージを概算すると、1億エントリあたり1TBになります。年間の時間的シャードごとに10億の証明書と事前証明書を保存する必要があると予想され、そのためには10TBが必要になります。年間の時間的シャードごとに約10TBを割り当てた個別のデータベースストレージを用意することを検討しましたが、コストがかかりすぎました。ログごとに12TBのストレージブロック(10TBと少しの余裕)を作成することにしました。これは、RDSによって冗長性のために複製されます。毎年、前年のシャードを凍結し、それほど高価ではない配信インフラストラクチャに移動して、そのストレージをライブシャードに再利用する予定です。
各CTログのRDSには、2台のdb.r5.4xlargeインスタンスを使用しています。これらの各インスタンスには、8つのCPUコアと128GBのRAMが含まれています。
Kubernetes
アプリケーションインスタンスを管理するためのいくつかの異なる戦略を試した後、Kubernetesを使用することにしました。Kubernetesにはかなりの学習曲線があり、この決定は軽々しく行われたものではありません。これはKubernetesを利用した最初のプロジェクトであり、Kubernetesを採用した理由の1つは、経験を積み、将来的にインフラストラクチャの他の部分にその知識を適用できる可能性があるためです。
Kubernetesは、デプロイメント、スケーリング、サービスディスカバリなどのオペレーター向けの抽象化を提供しており、これらを自分で構築する必要はありません。TrillianリポジトリのKubernetesデプロイメントマニフェストの例を使用して、デプロイメントを支援しました。
Kubernetesクラスターは、Kubernetes APIを処理するコントロールプレーンと、コンテナー化されたアプリケーションが実行されるワーカーノードの2つの主要コンポーネントで構成されています。Amazon EKSにKubernetesコントロールプレーンを管理させることにしました。
各CTログのワーカーノードプールには、4台のc5.2xlarge EC2インスタンスを使用しています。これらの各インスタンスには、8つのCPUコアと16GBのRAMが含まれています。
アプリケーションソフトウェア
Kubernetesクラスターで実行する3つの主要なCTコンポーネントがあります。
証明書トランスペアレントフロントエンド、つまりCTFEは、RFC 6962エンドポイントを提供し、それらをTrillianバックエンドのgRPC APIリクエストに変換します。
Trillianは、それ自体を「透過的で、高度にスケーラブルで、暗号化によって検証可能なデータストア」と表現しています。基本的に、Trillianは、CTFEを介してCTログのバックエンドとして使用できるMerkleツリーを介して、一般化された検証可能なデータストアを実装します。Trillianは、ログ署名者とログサーバーの2つのコンポーネントで構成されています。ログ署名者の機能は、受信するリーフデータ(CTの場合は証明書)を定期的に処理し、それらをMerkleツリーに組み込むことです。ログサーバーは、CT API監視リクエストを満たすために、Merkleツリーからオブジェクトを取得します。
{kind=link}
負荷分散
トラフィックは、Kubernetes NginxイングレスサービスにマッピングされたAmazon ELBを介してCTログに入ります。イングレスサービスは、複数のNginxポッド間でトラフィックのバランスを取ります。Nginxポッドは、CTFEポッドにトラフィックのバランスを取るCTFEサービスにトラフィックをプロキシします。
このNginxレイヤーで、IPとユーザーエージェントに基づくレート制限を採用しています。
ロギングと監視
TrillianとCTFEは、Prometheusメトリクスを公開しており、これを監視ダッシュボードとアラートに変換します。ログが信頼されるようにするために、CTポリシーで規定されている99%の稼働時間よりも高いCTログエンドポイントのサービスレベル目標を設定することが不可欠です。DaemonSetで実行されているFluentDポッドは、ログを集中型ストレージに出荷して、さらに分析します。
ログの安定性と正確性のさまざまな側面を監視するために使用されるct-woodpeckerという名前の無料のオープンソースツールを開発しました。このツールは、サービスレベル目標を確実に達成するための重要な要素です。各ct-woodpeckerインスタンスは、CTログを含むAmazon VPCの外部で実行されます。
将来の効率改善
将来、システムの効率を改善できる可能性のある方法を以下に示します。
- Trillianは、同じ中間証明書の多くの重複コピーを含む、各証明書チェーンのコピーを保存します。Trillianでこれらを重複排除できるようになれば、ストレージコストが大幅に削減されます。これが可能で合理的かどうかを調査する予定です。
- IO1ブロックストレージとプロビジョニングされたIOPSよりも安価なストレージ形式を正常に使用できるかどうかを確認します。
- KubernetesワーカーEC2インスタンスのサイズを削減したり、EC2インスタンスの使用数を減らしたりできるかどうかを確認します。
Let's Encryptをサポートする
サービスを提供するために、ユーザーとサポーターのコミュニティからの貢献に依存しています。スポンサーシップについて詳しく知りたい場合は、sponsor@letsencrypt.orgまでメールでお問い合わせください。可能な場合は、個別の貢献をお願いします。